SOFTWARE DEVELOPMENT / DESIGN COMPUTATION / ART /
DATA SCIENCE / MACHINE LEARNING / RESEARCH
Lexigraph
Lexigraph is a full-stack development of a vocabulary-building application.
It uses a thesaurus approach to help users acquire new vocabularies with words they have already learned. By visualizing lexical relations between a new word and its synonyms familiar to the user, the application hopes to improve comprehension.
To achieve this, the application utilizes WordNet API from NLTK and visualizes lexical connections between a search word its synonyms as a graph. Users can interact with the lexical graph to indicate known or unknown words by highlighting or unhighlighting. Meanwhile, a clustering algorithm running in the backend partitions Google's Web Trillion Word Corpus based on the distribution of known words. It then assigns each partition a "known probability" by the density of known words within. Using these probability assignments, the application will automatically predict "known" synonyms by highlighting them in the lexical visualization. As users continue to interact with the application, the prediction gains accuracy in real-time.
This is a three-week prototype for CMU 15112: Fundamentals of Programming and Computer Science.
Type: desktop application
Role: full-stack development
Implementation: Python, Tkinter
Date: 2018
︎︎︎View Source
Menu
In the main interface, users can choose the following modes to interact with new vocabularies.
- lexigraph: visualizes the lexical relationships between a word and its synonyms.
- explore: get the latest usage from Marriam Webster
- search: look up a new word and return the result as a lexical graph
- dictionary: conventional dictionary definition provided by WordNet
- pair: a timed synonym paring game to strengthen memory
- archive: find all previously searched words

Looking Up A New Word
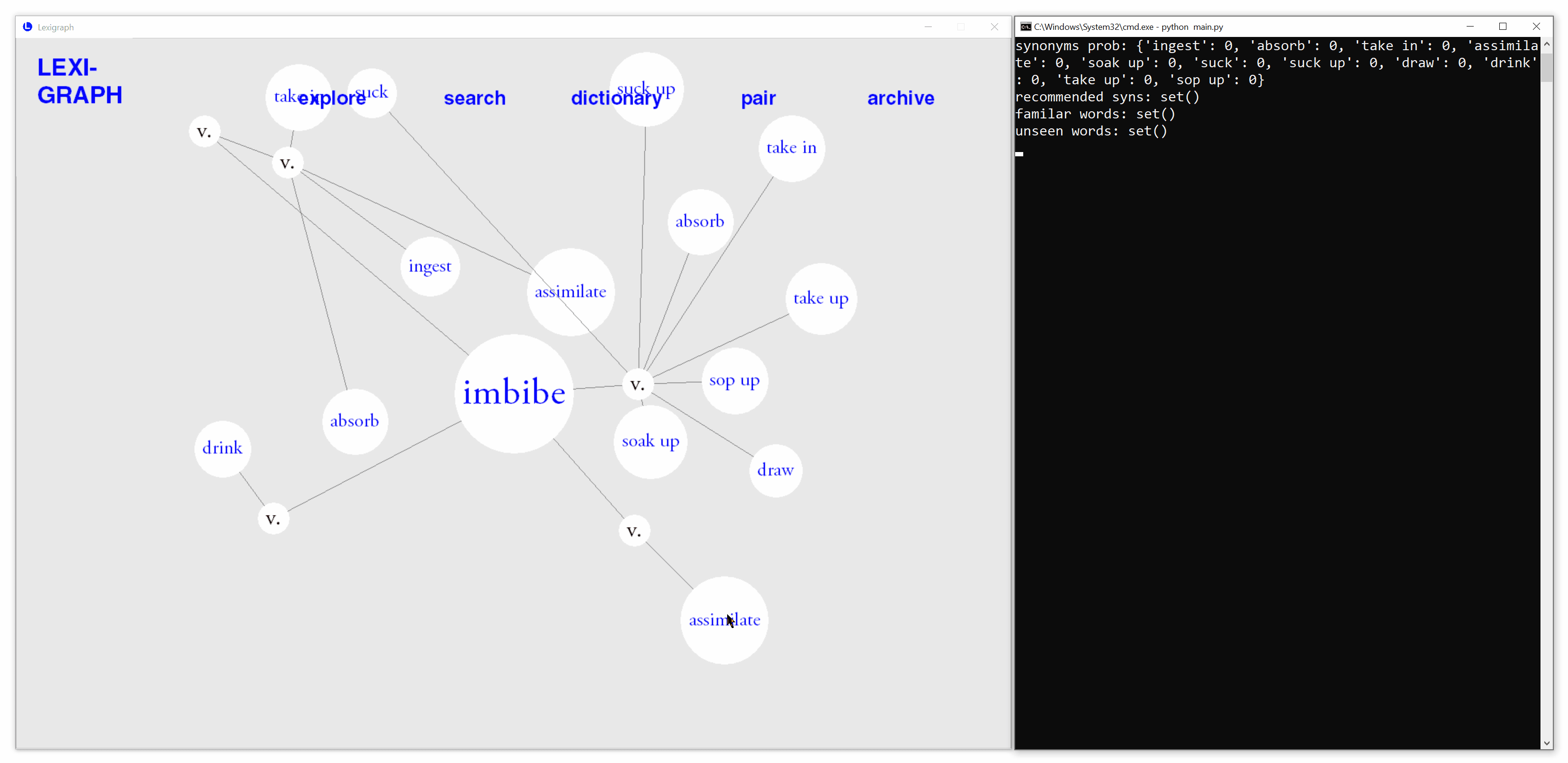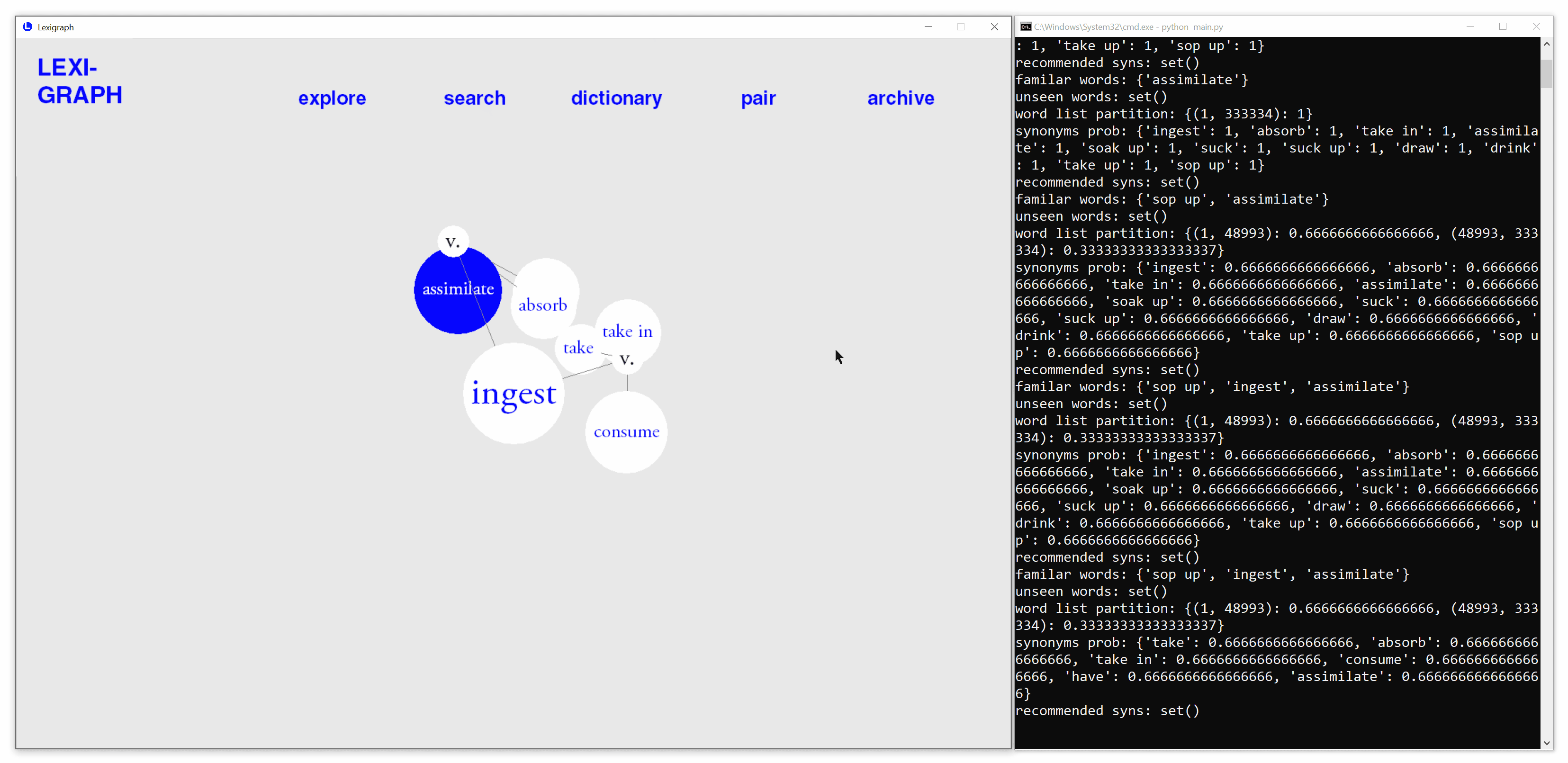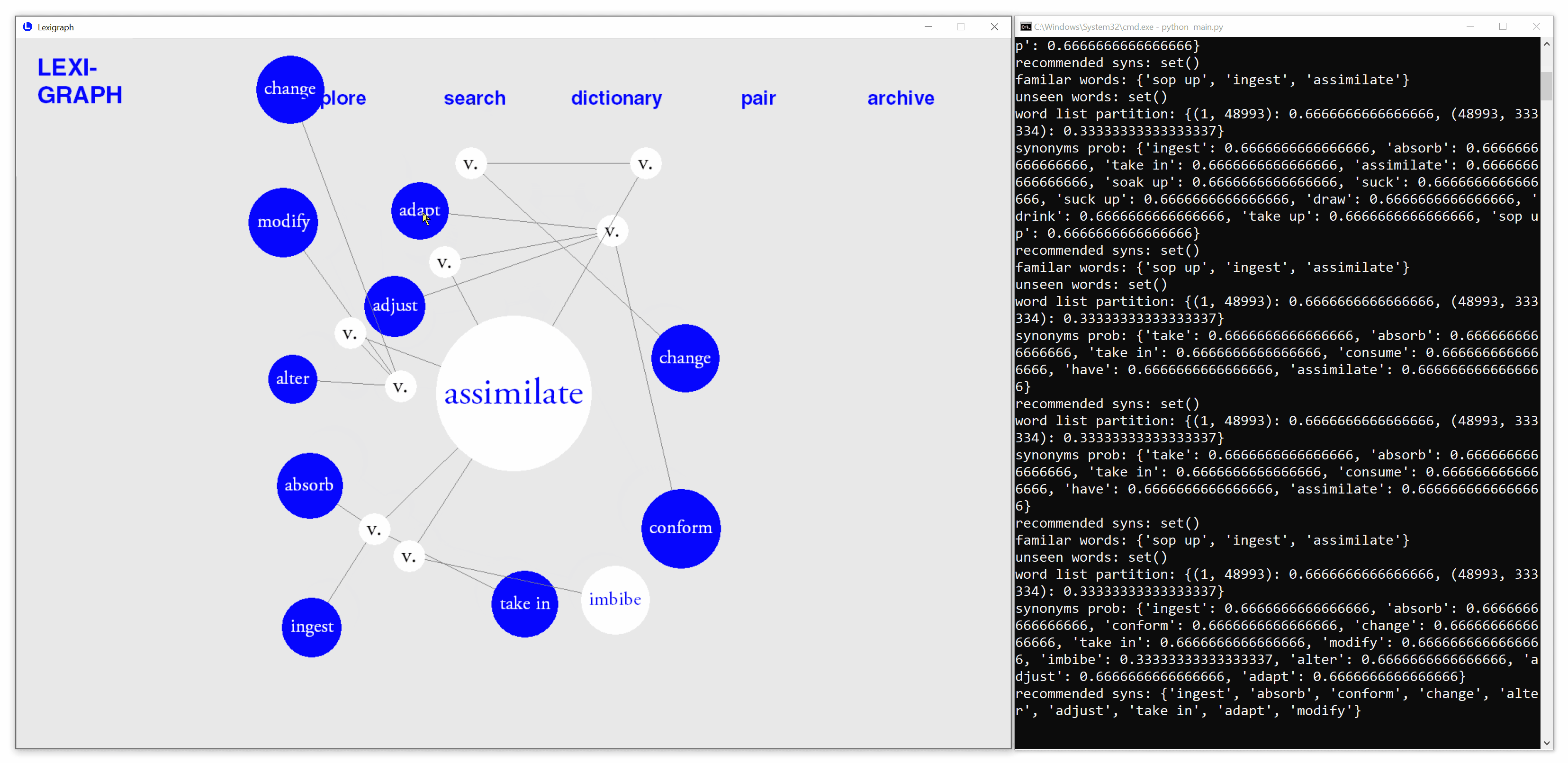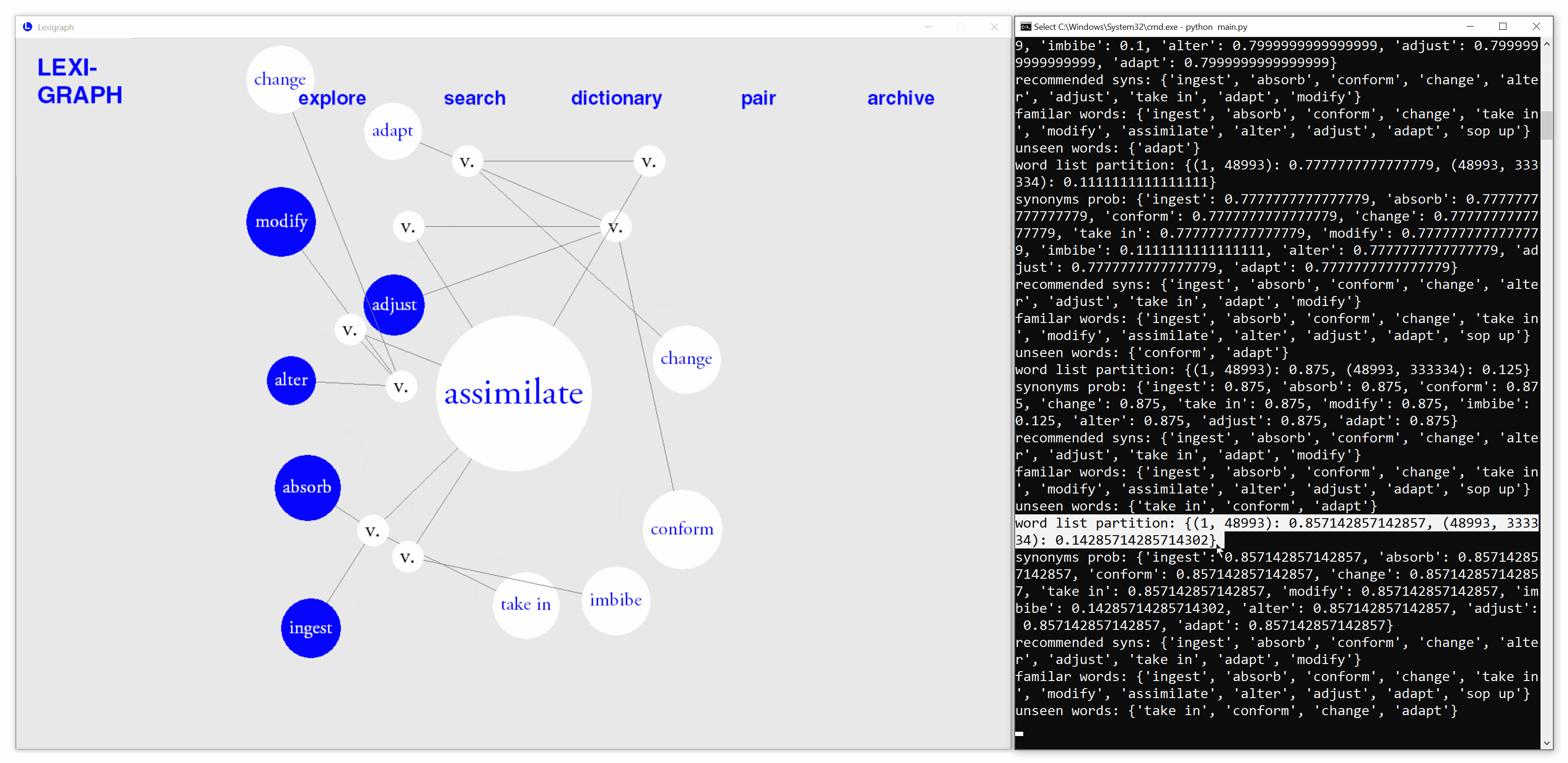
Type in a word in the search mode to obtain a lexigraph. The synonyms are organized by search word's part-of-speech (POS) tags. Hover over each POS tag to see its definition.

Interact to Indicate Word Familiarity
Click to highlight or unhighlight synonyms to indicate whether it is known. Lexigraph will remember words indicated as familiar or unfamiliar by the user.
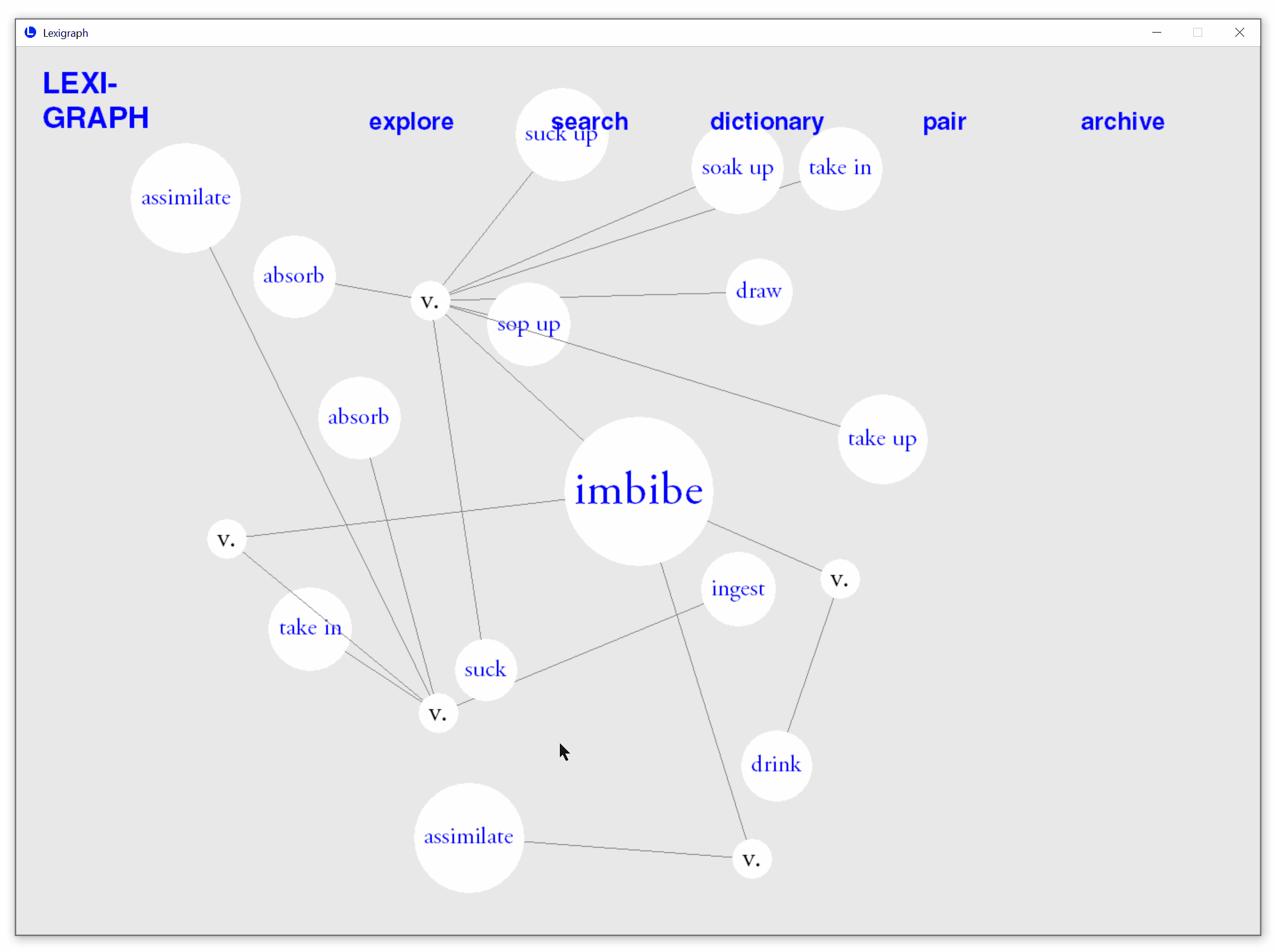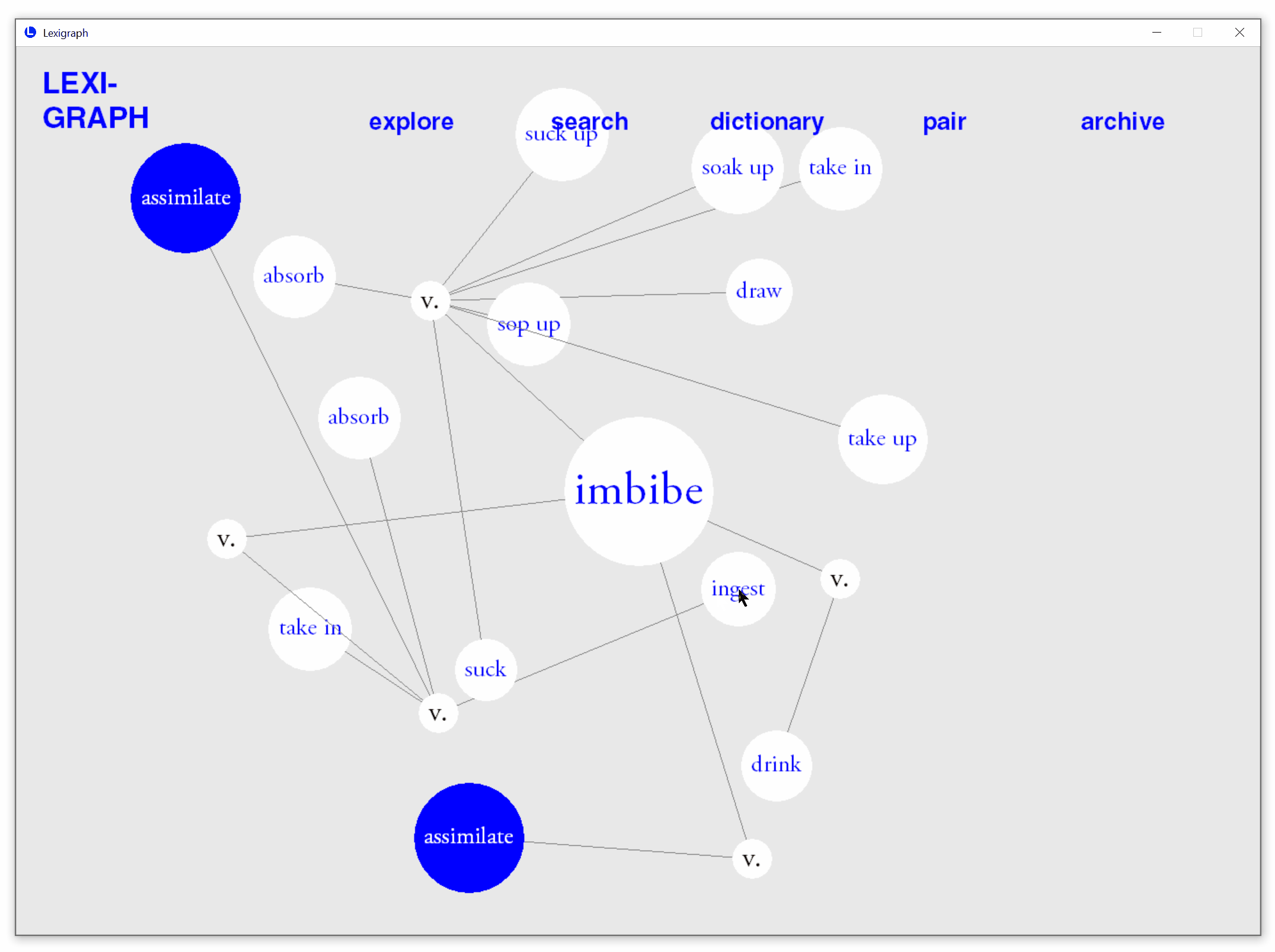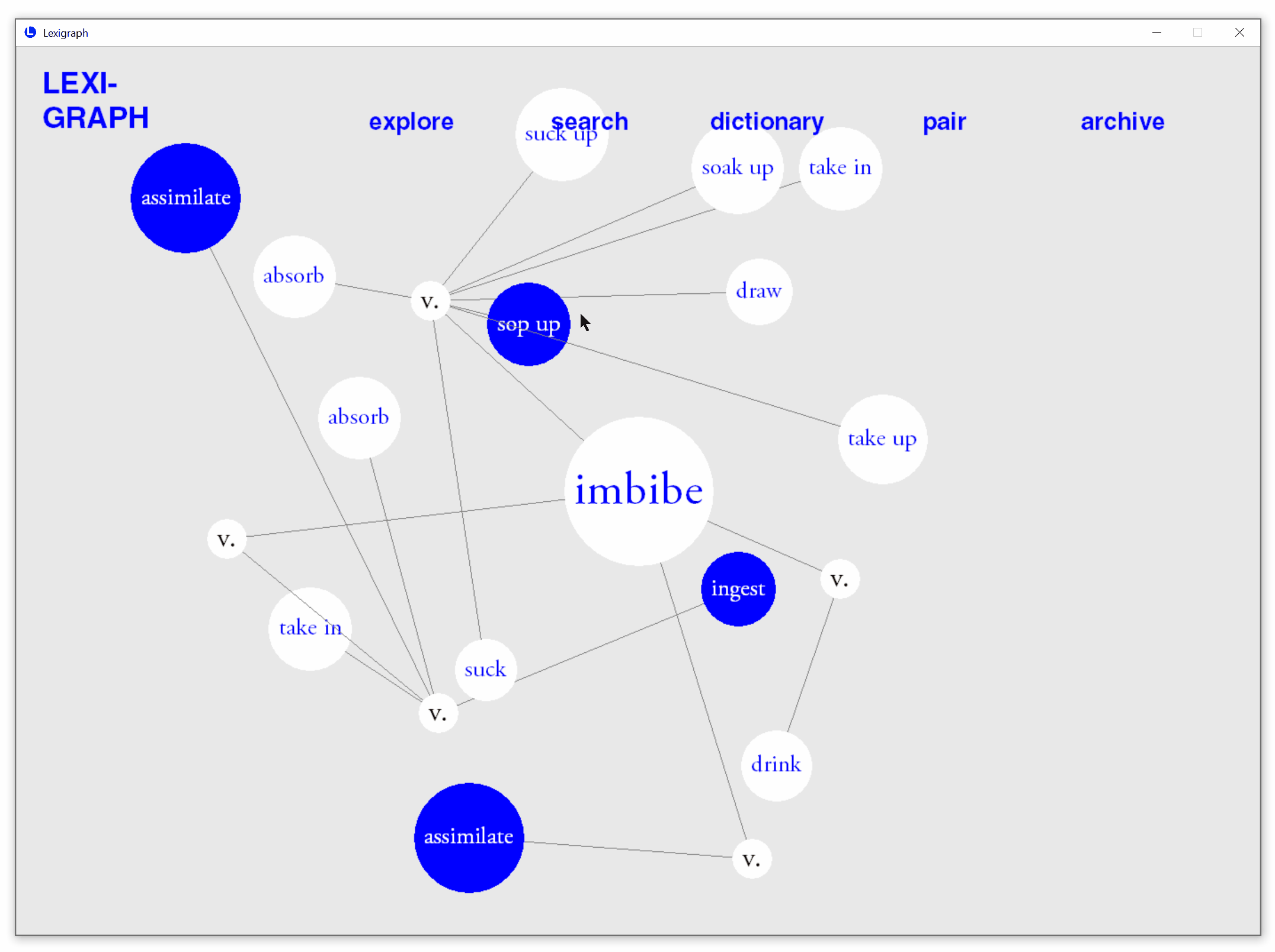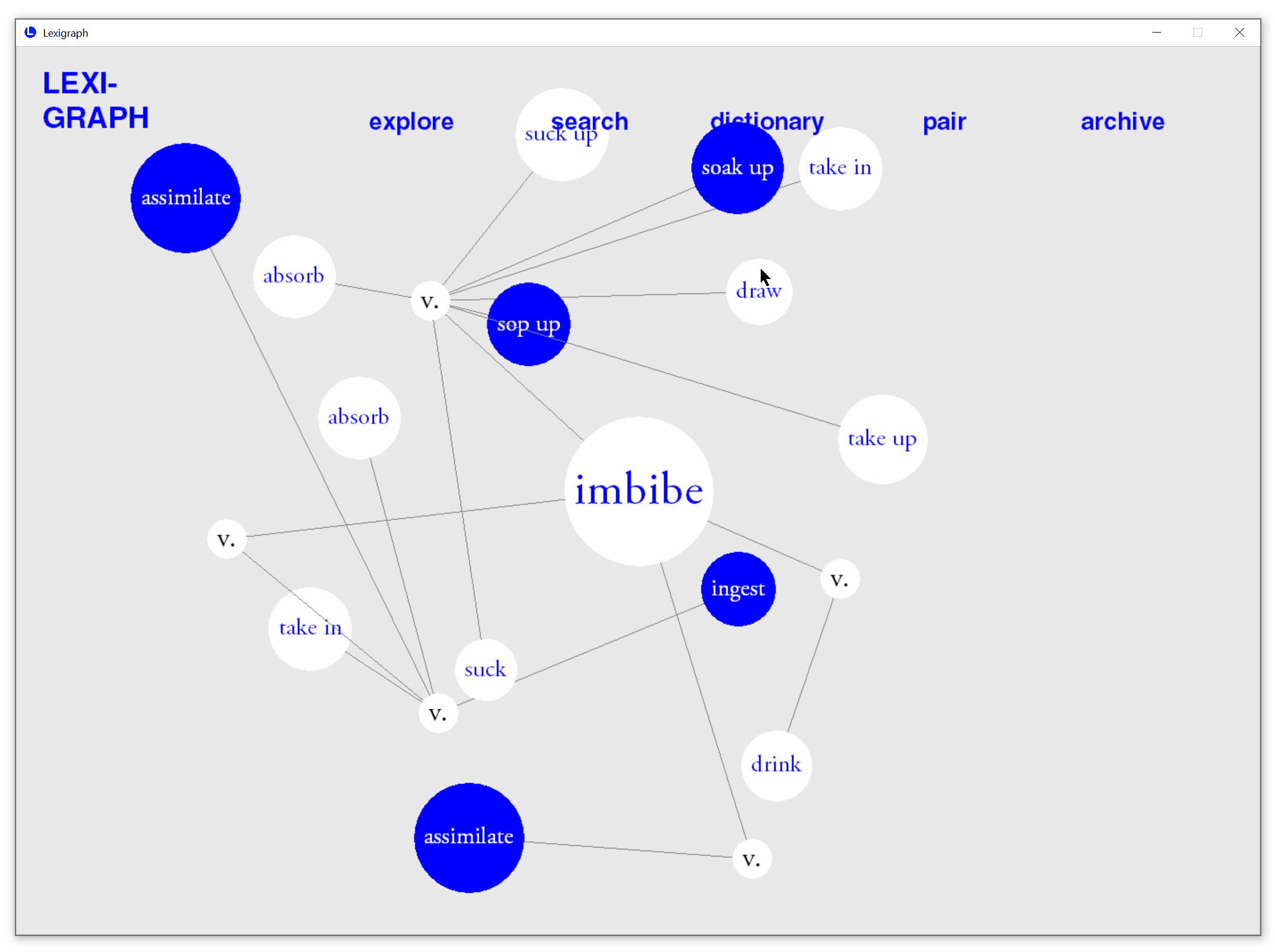
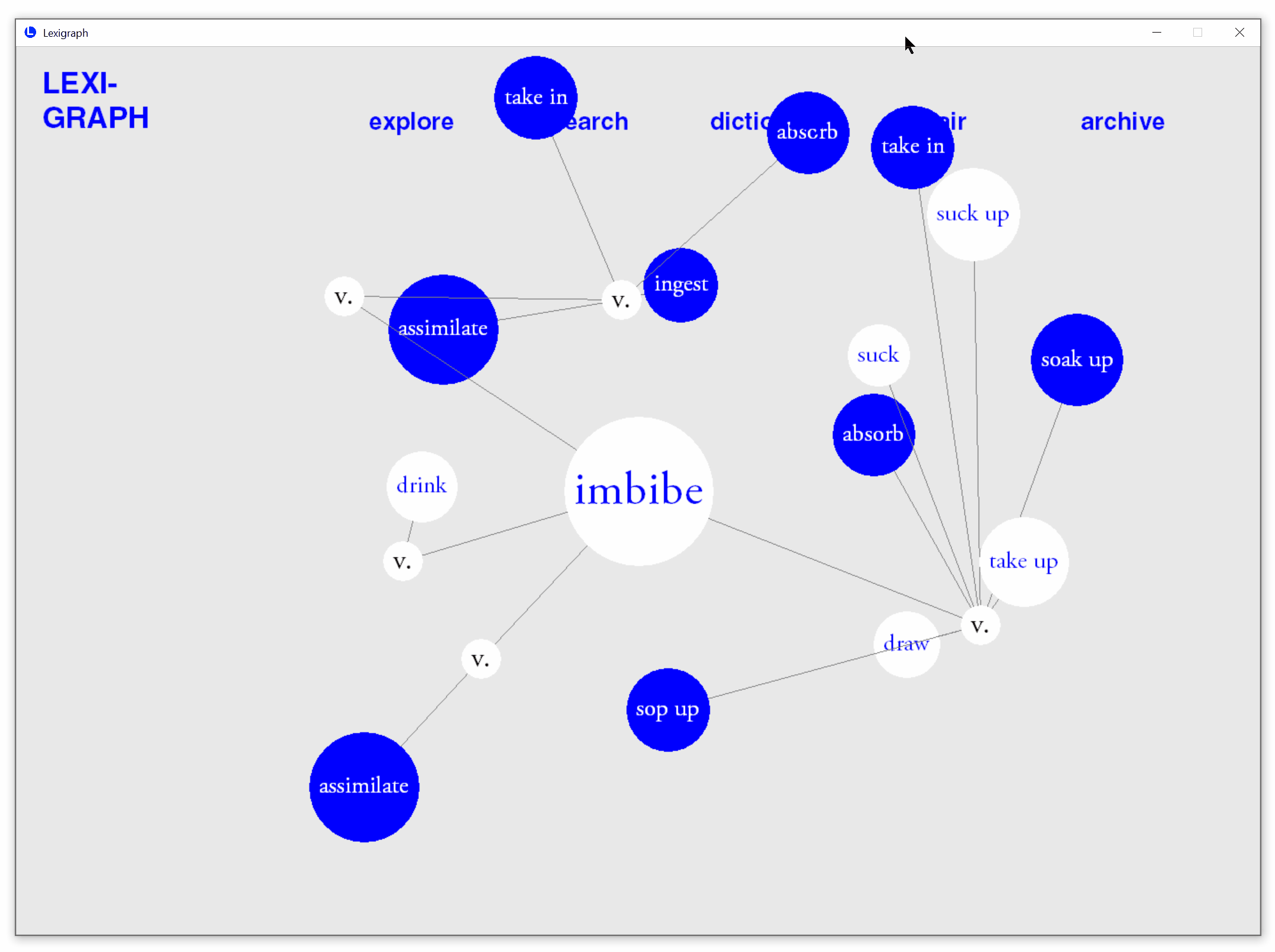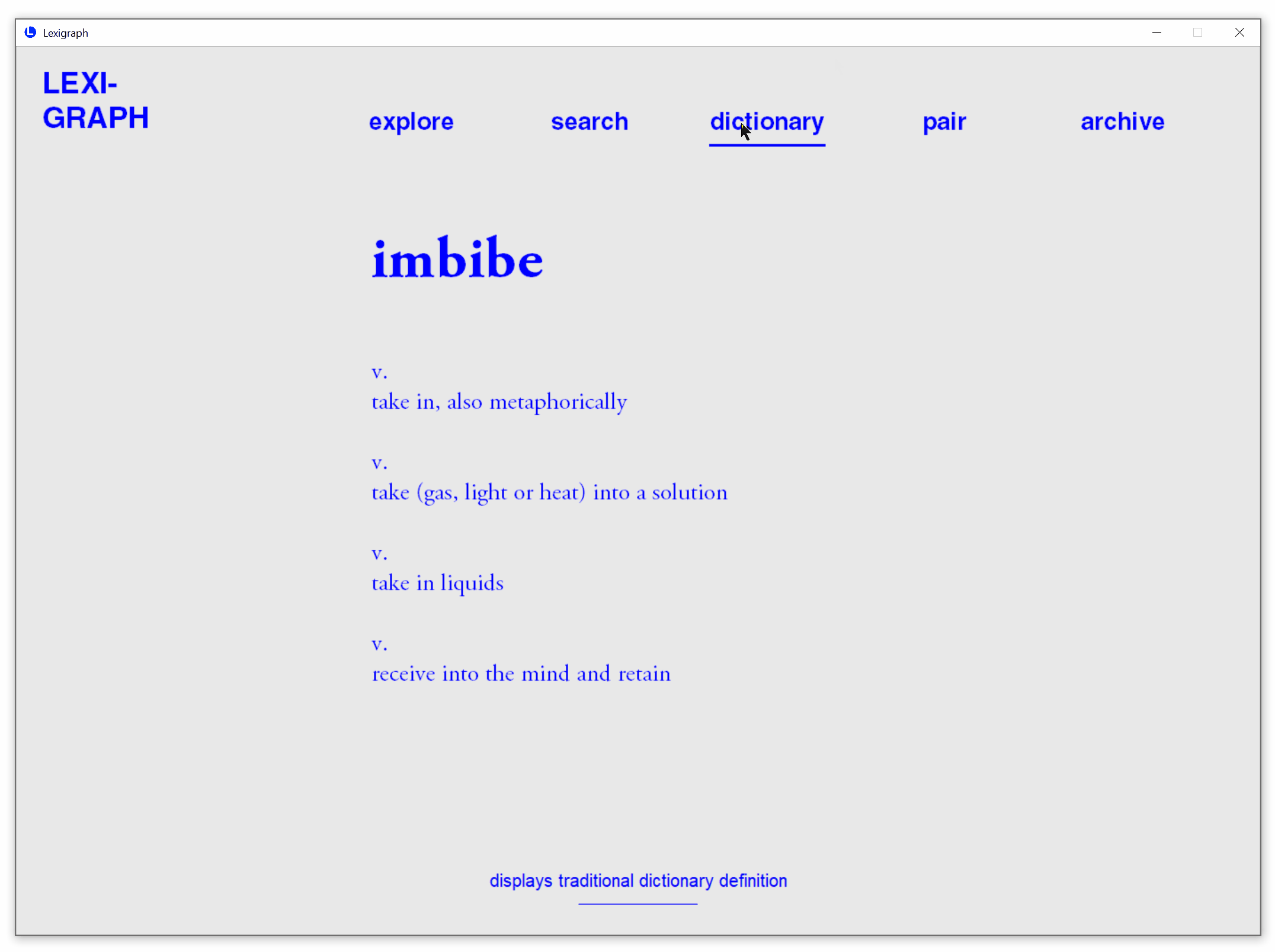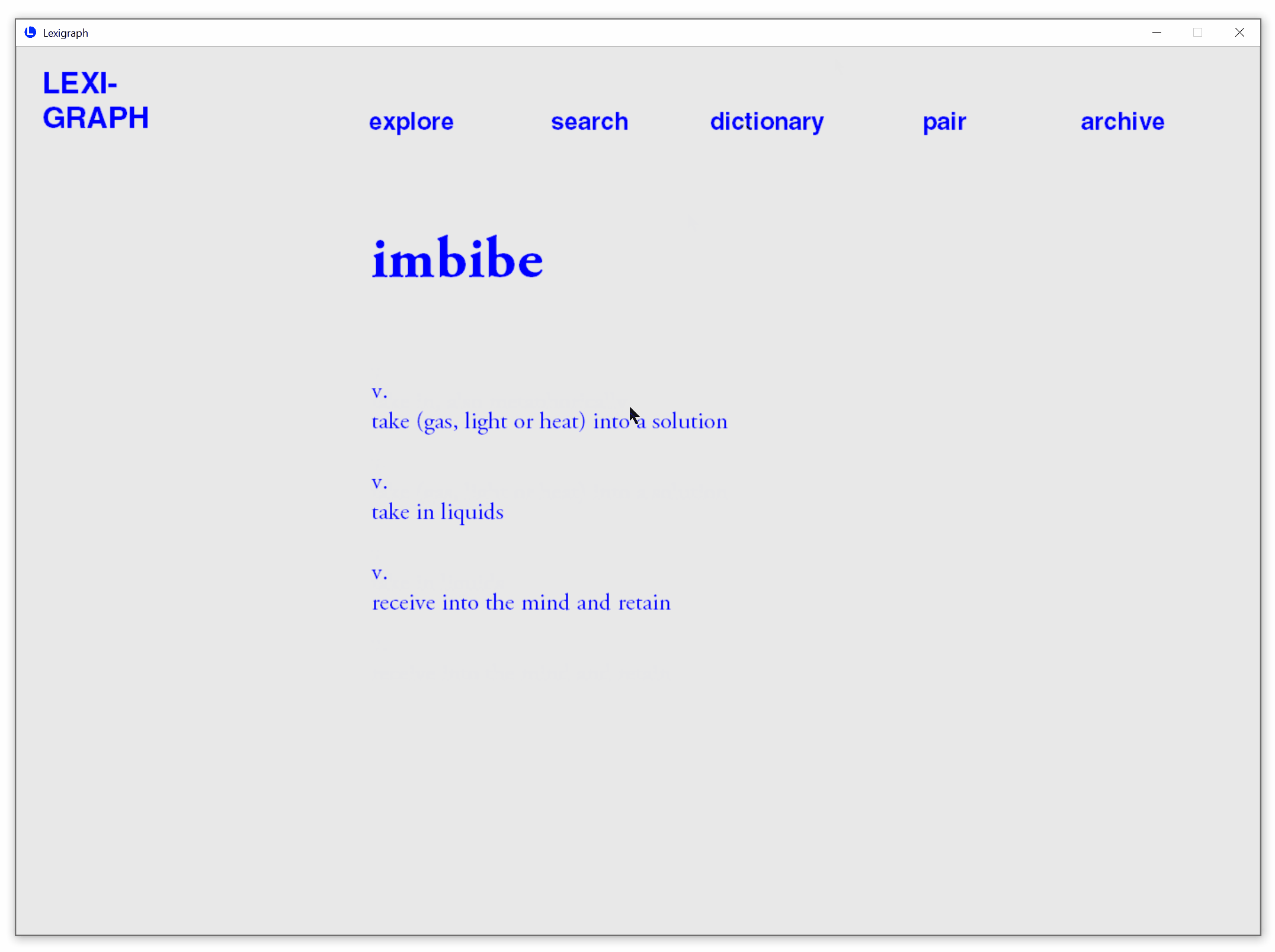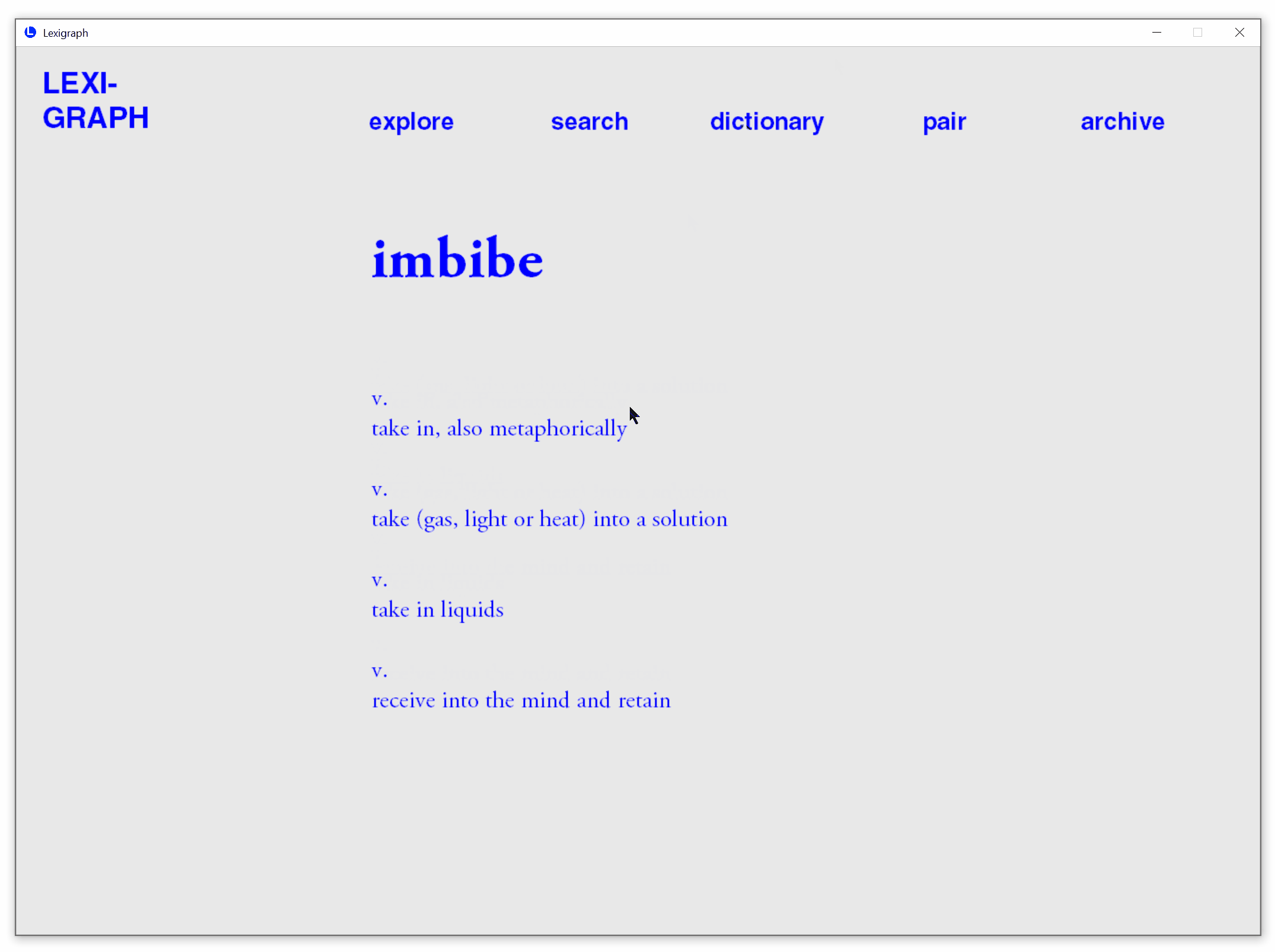
Automatic prediction of known synonyms
Based on real-time user interactions, the application estimate words that are likely to be known by users and automatically highlights them in each search.

Conventional Dictionary View
View conventional dictionary definitions.
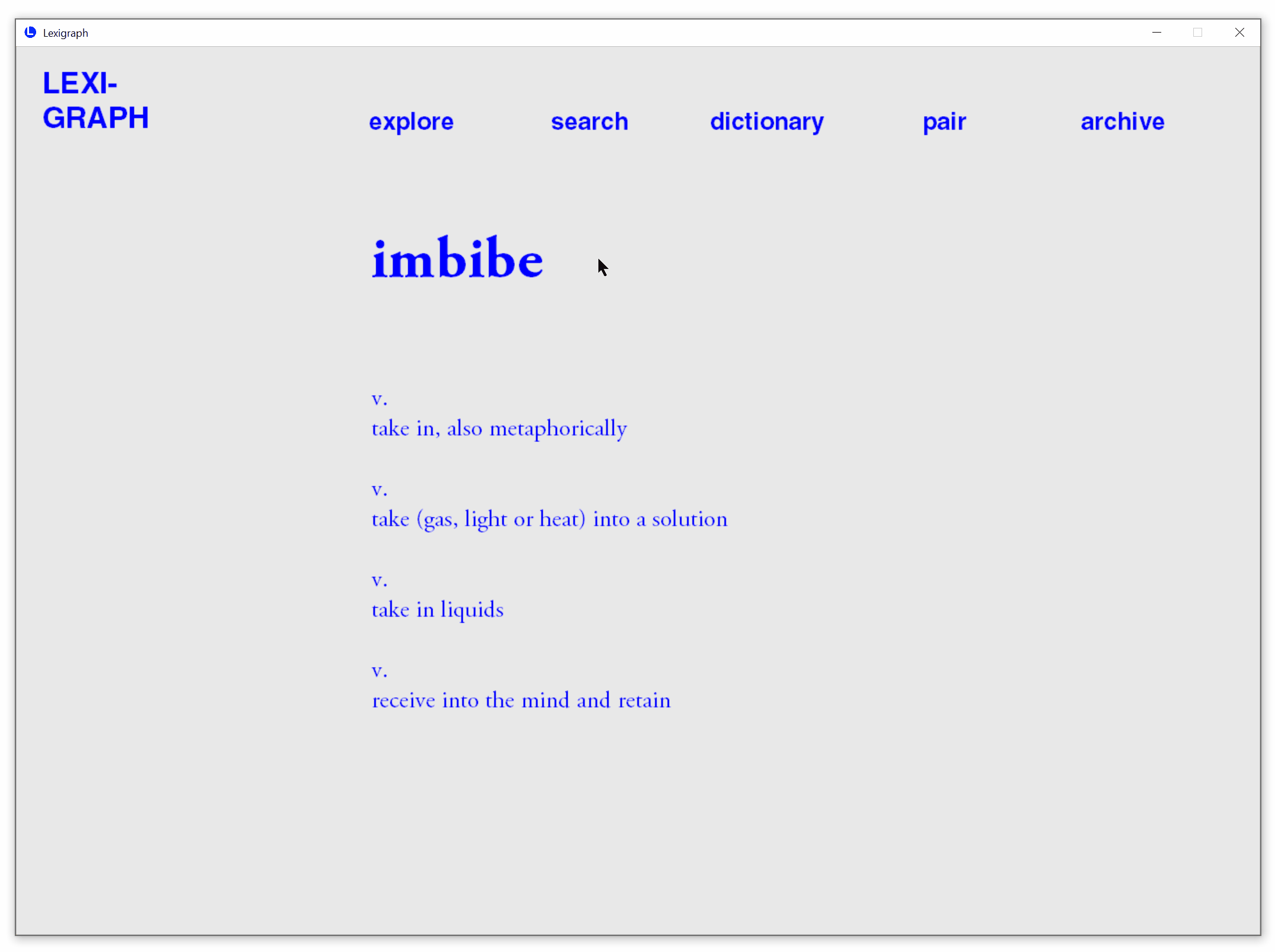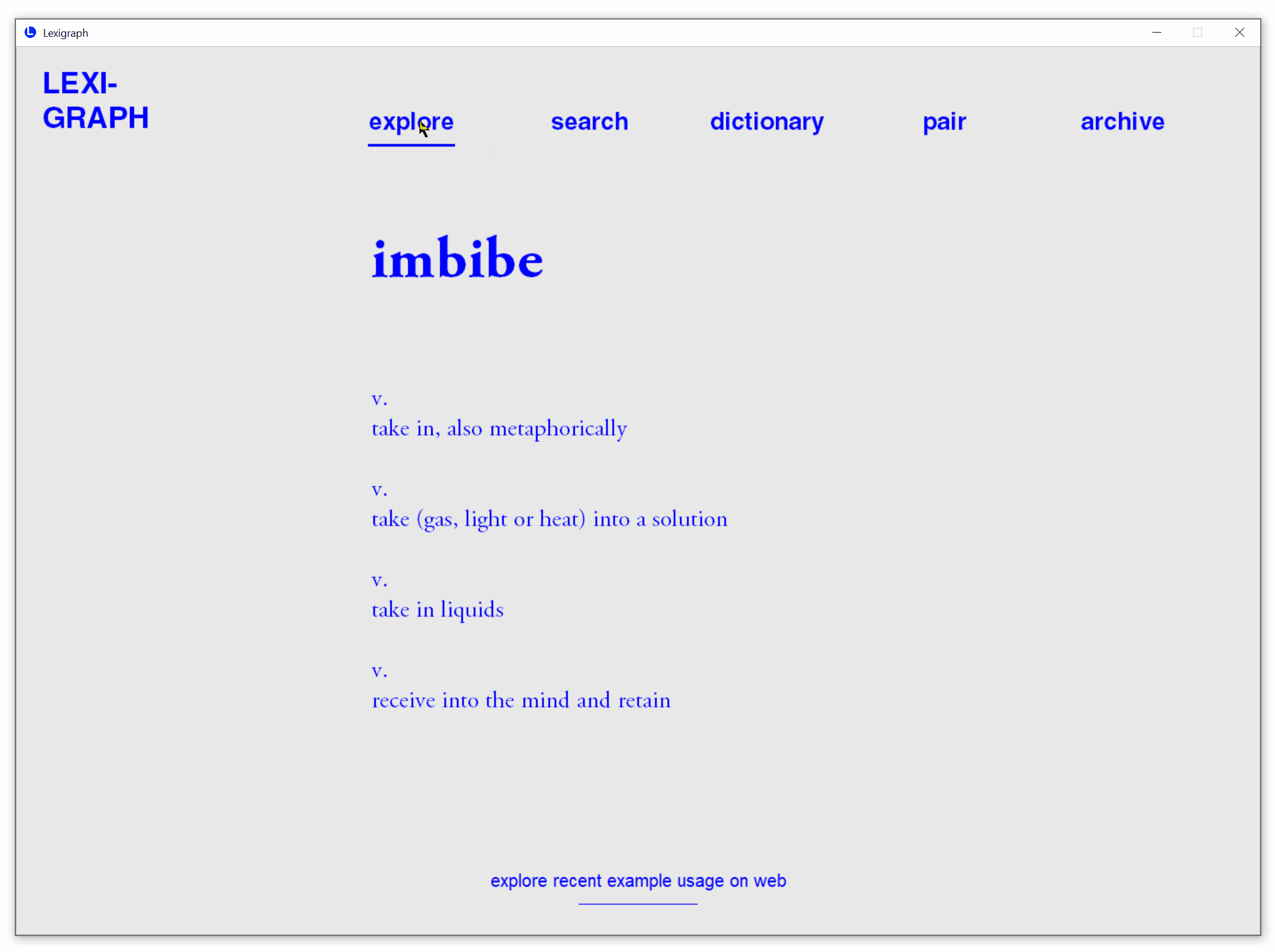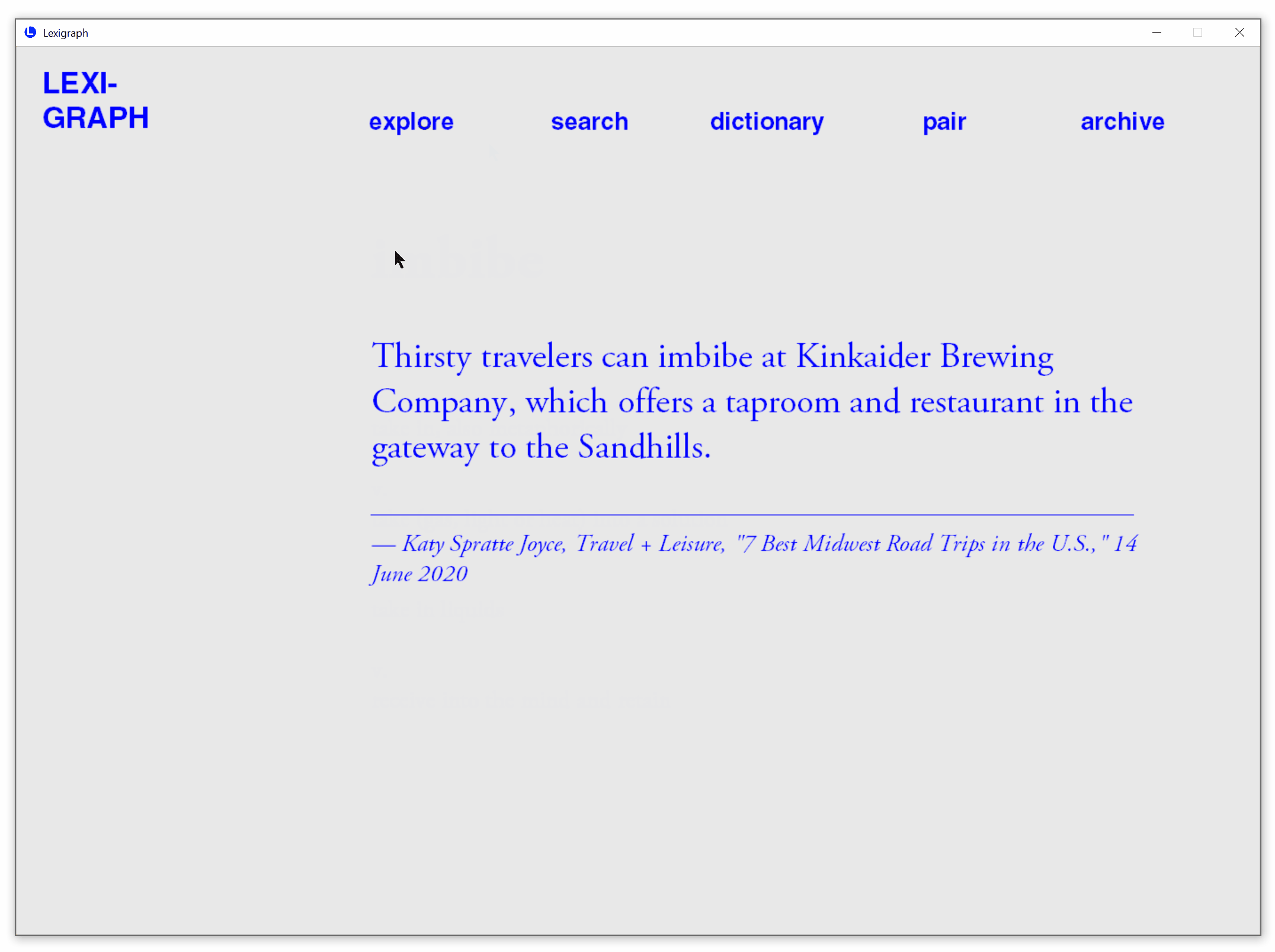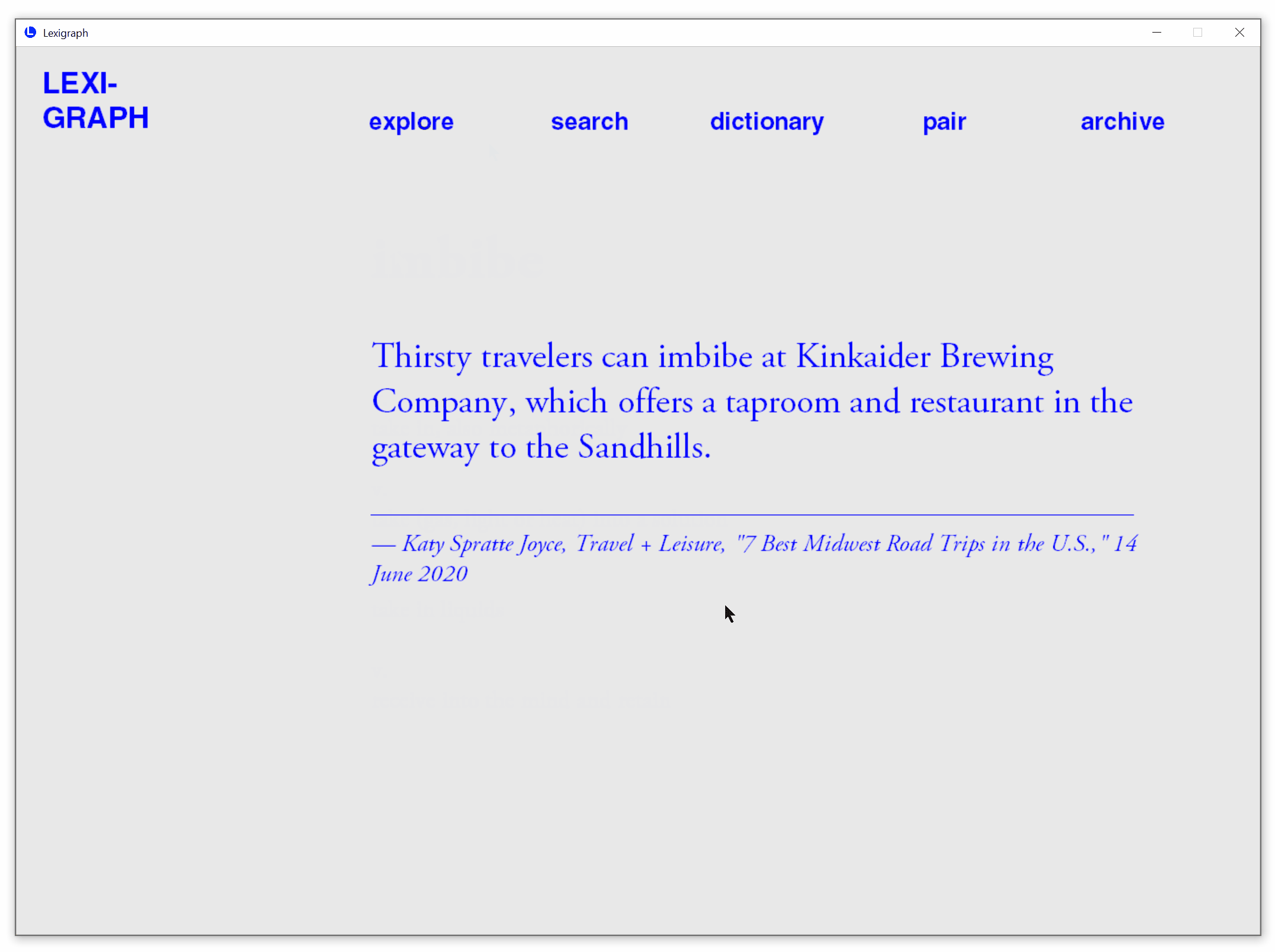
Get The Latest Usage from The Web
See the latest example usage from Merriam Webster.
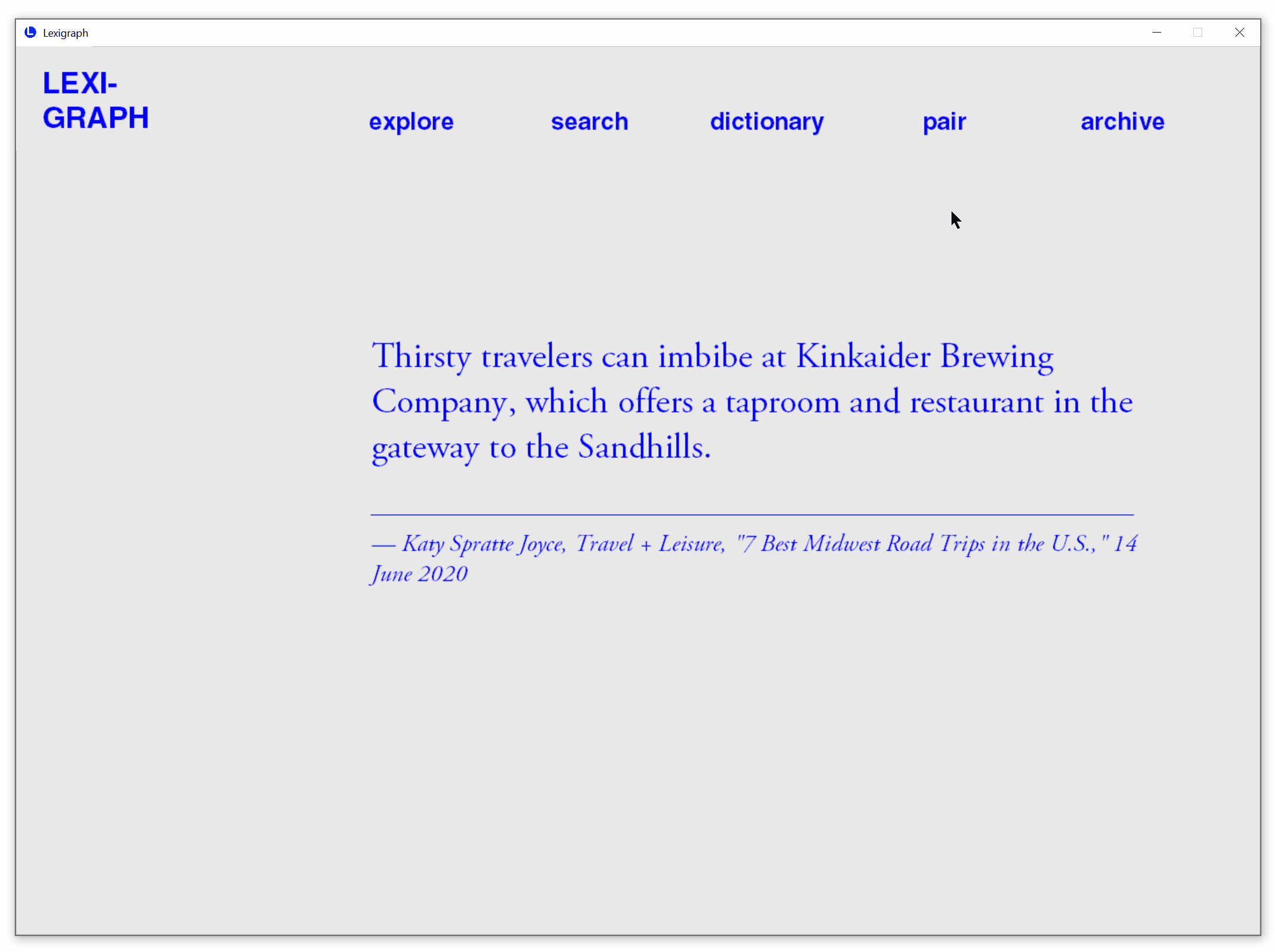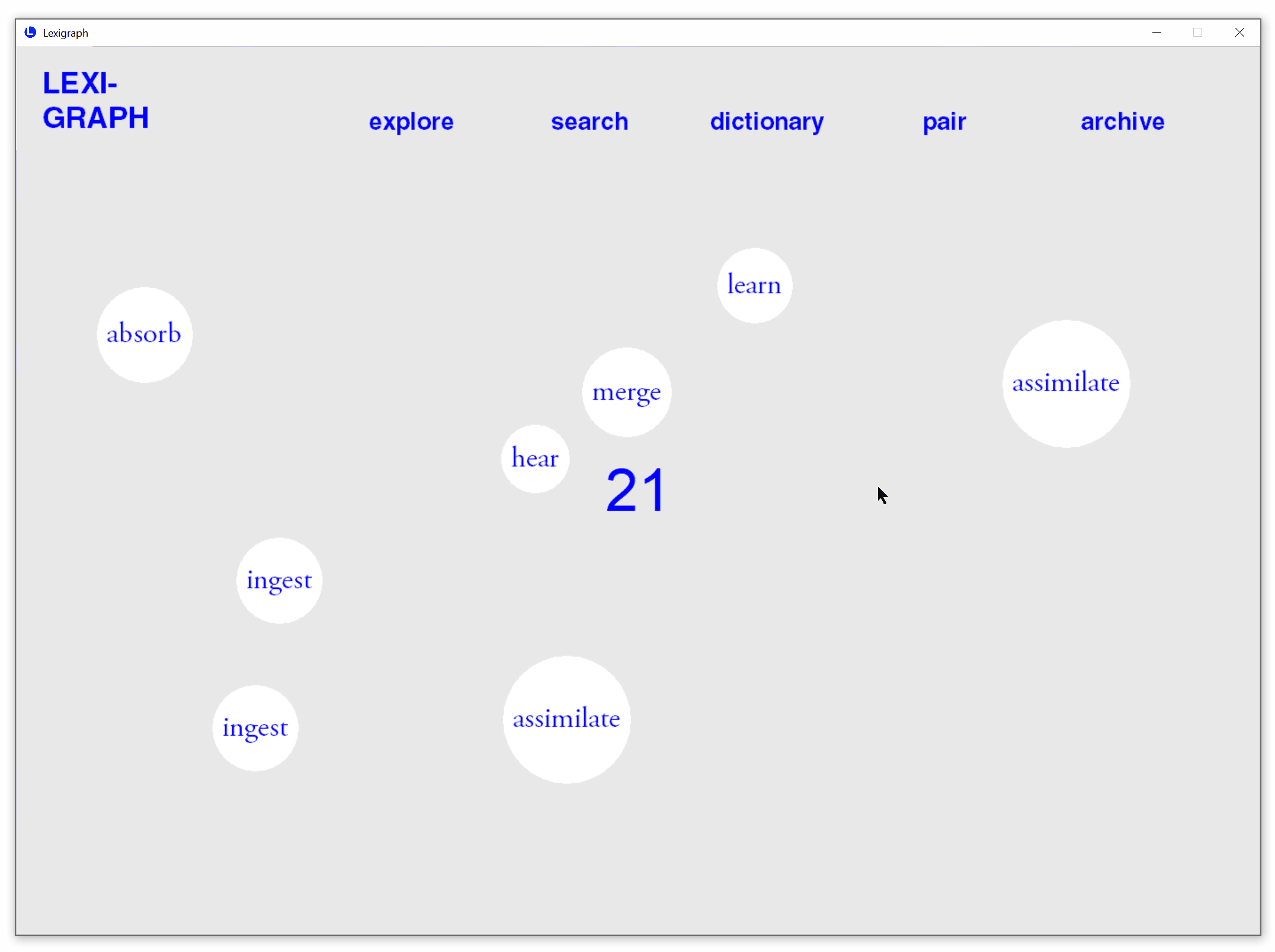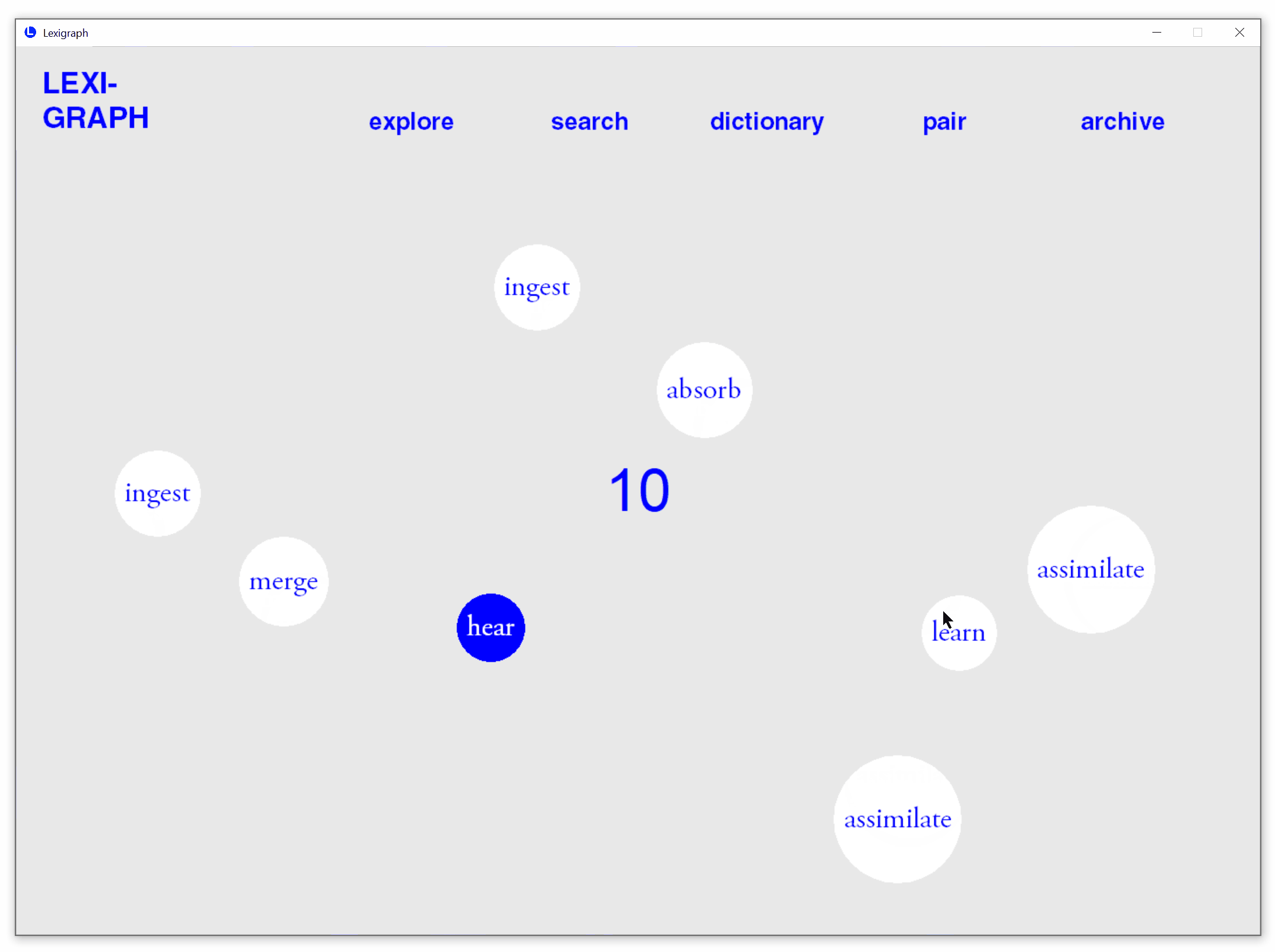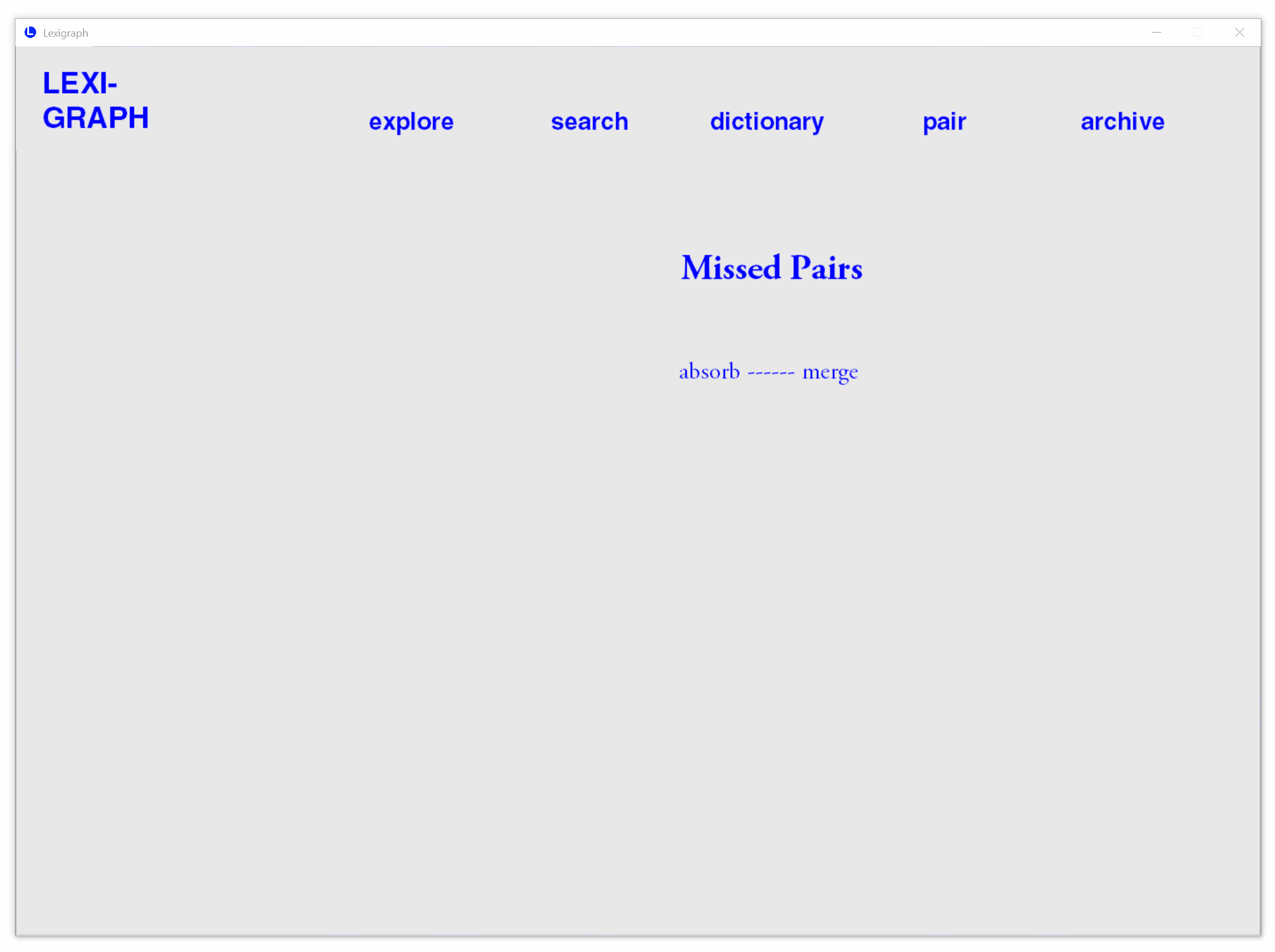
Paring Game to Strengthen Retention
A timed word paring game in which users pair new vocabularies with known synonyms.
Review Learned Words
Stores all previously searched words for easy retrieval.
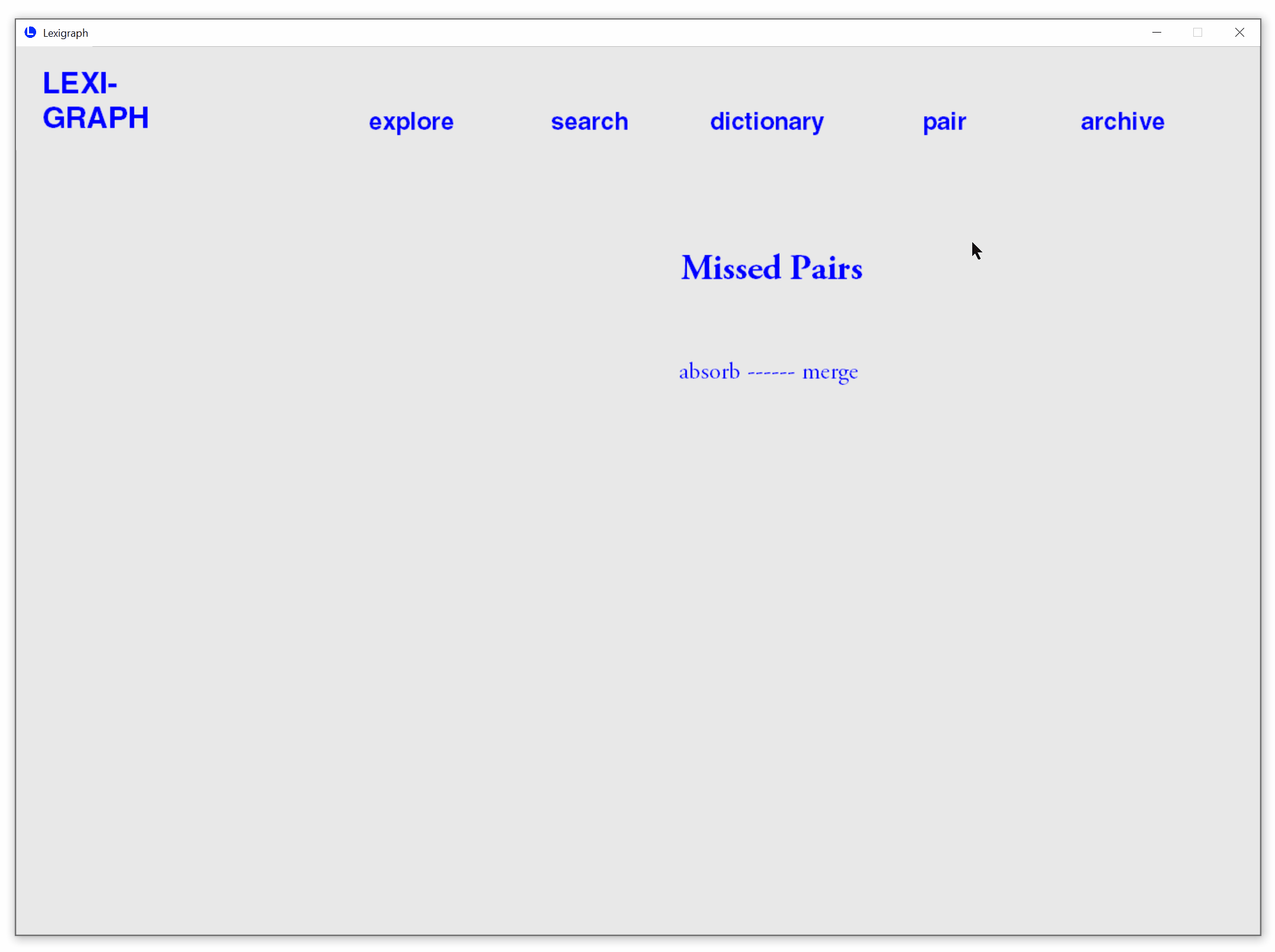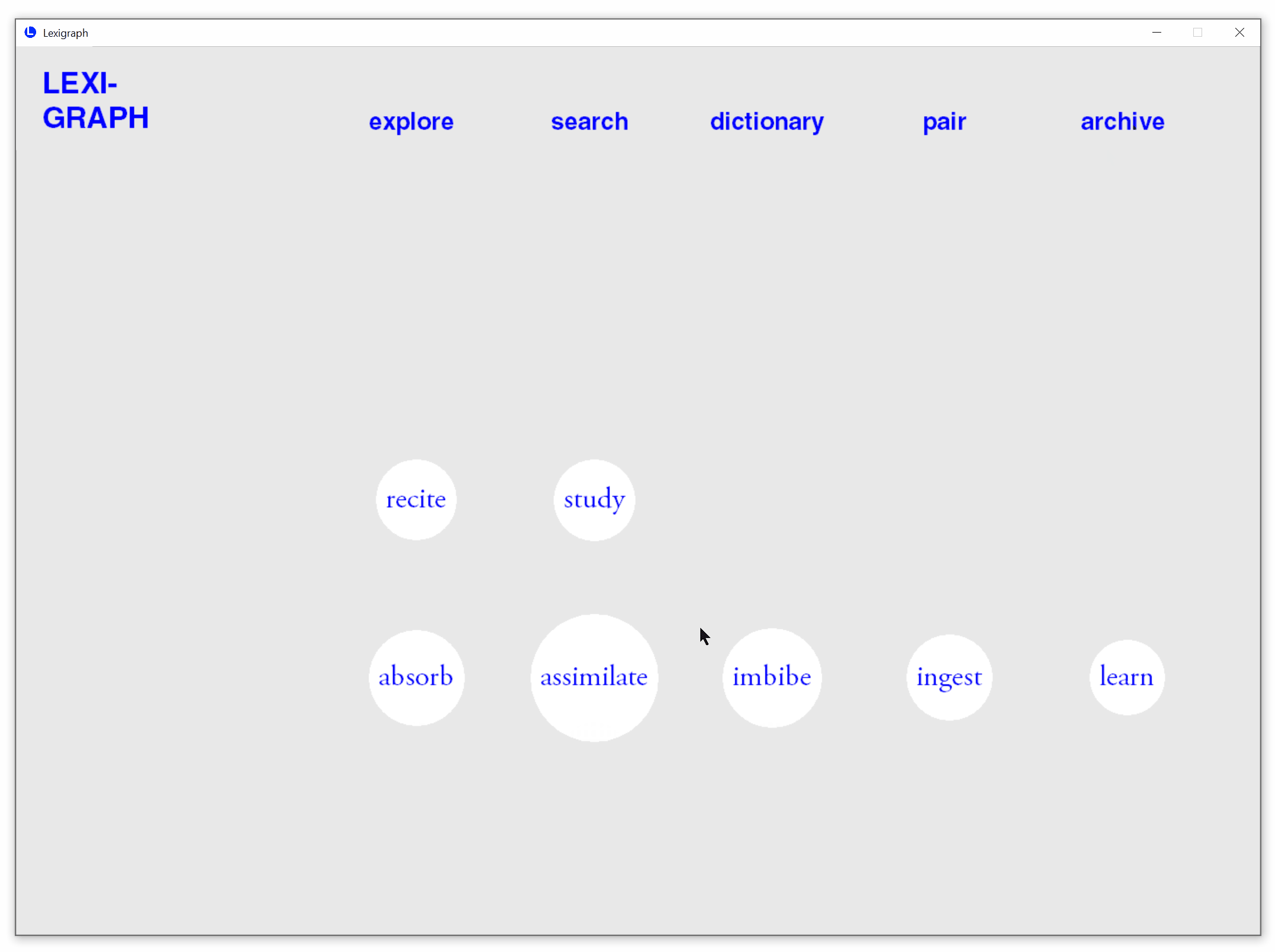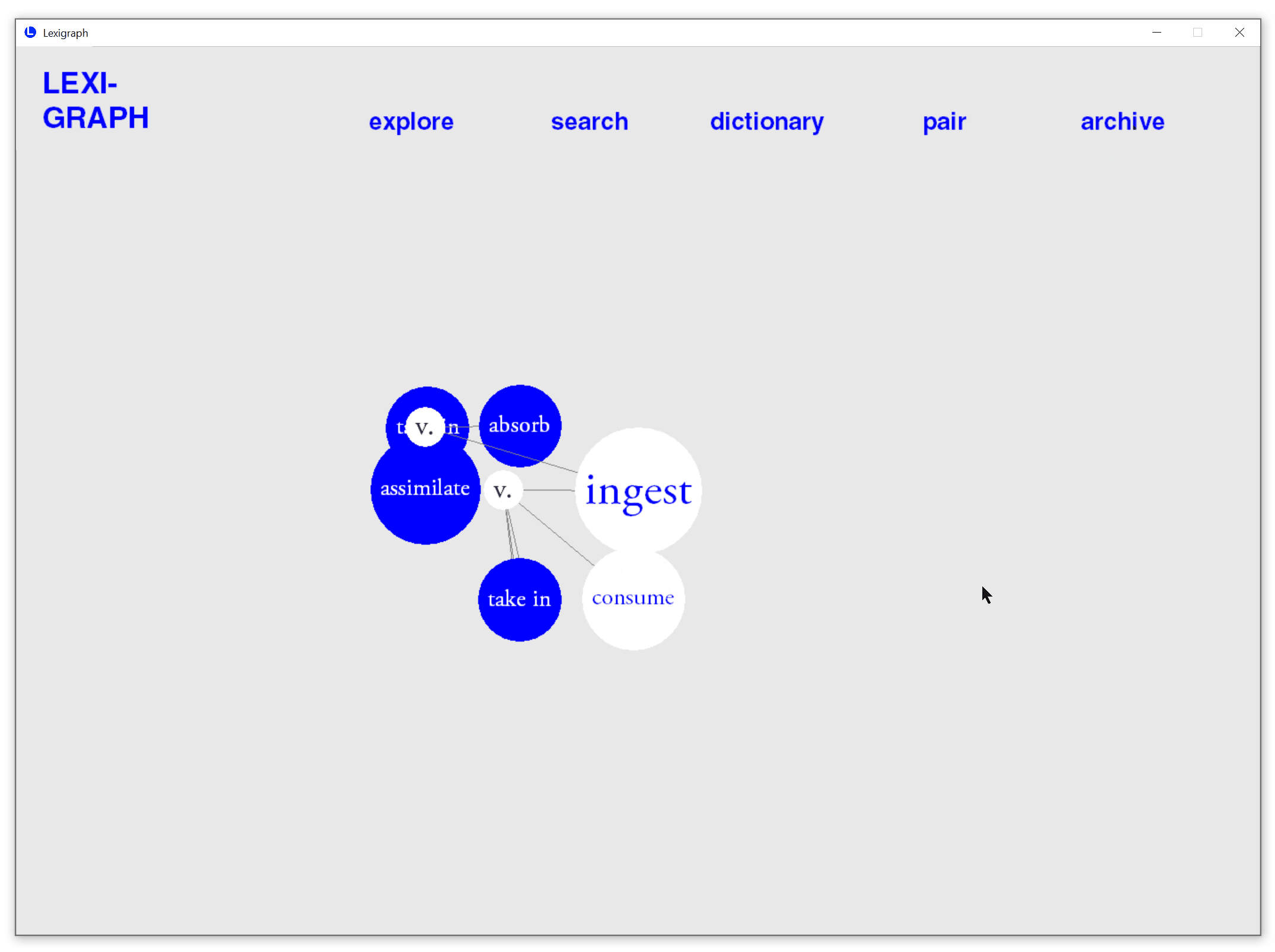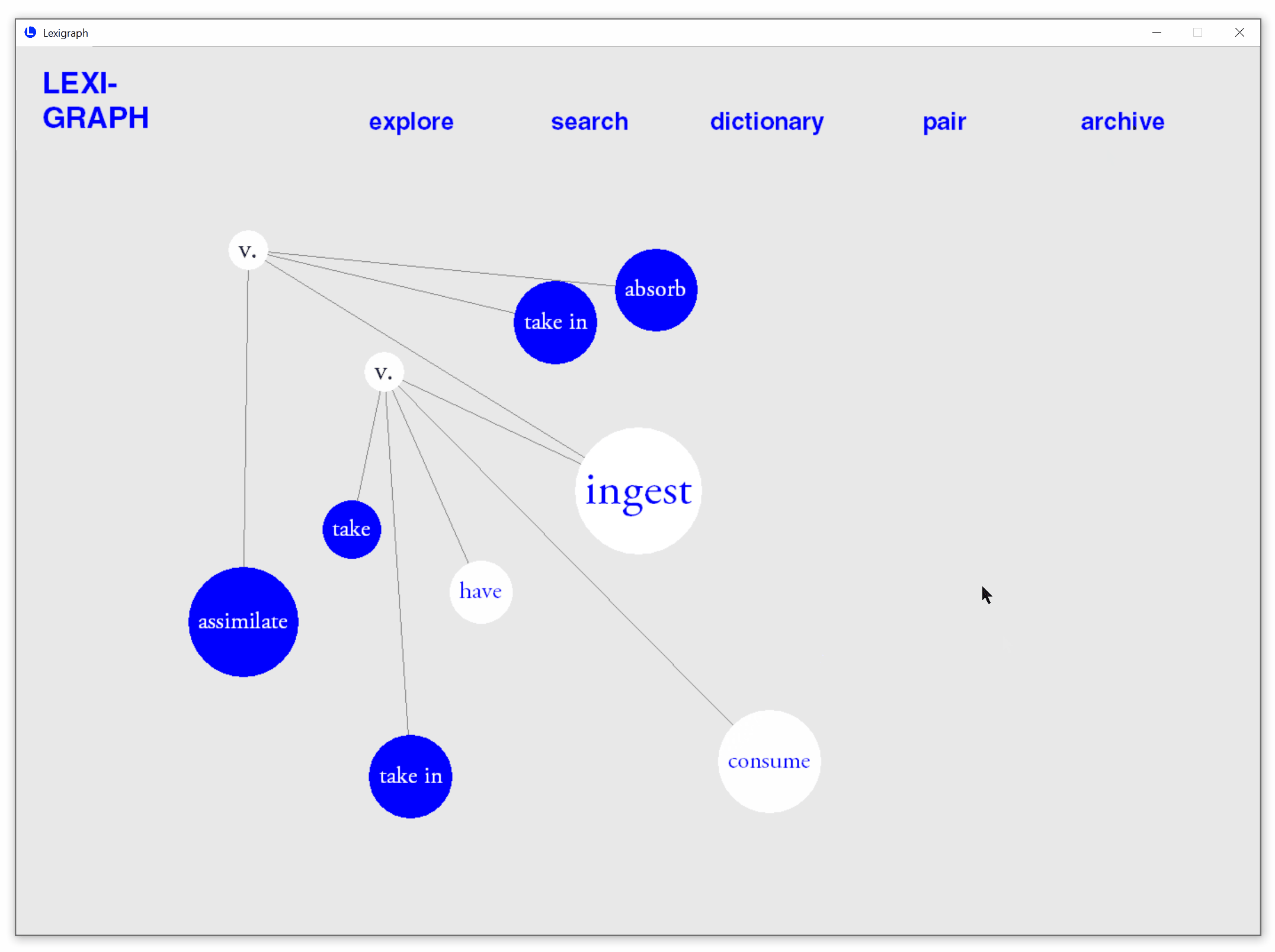
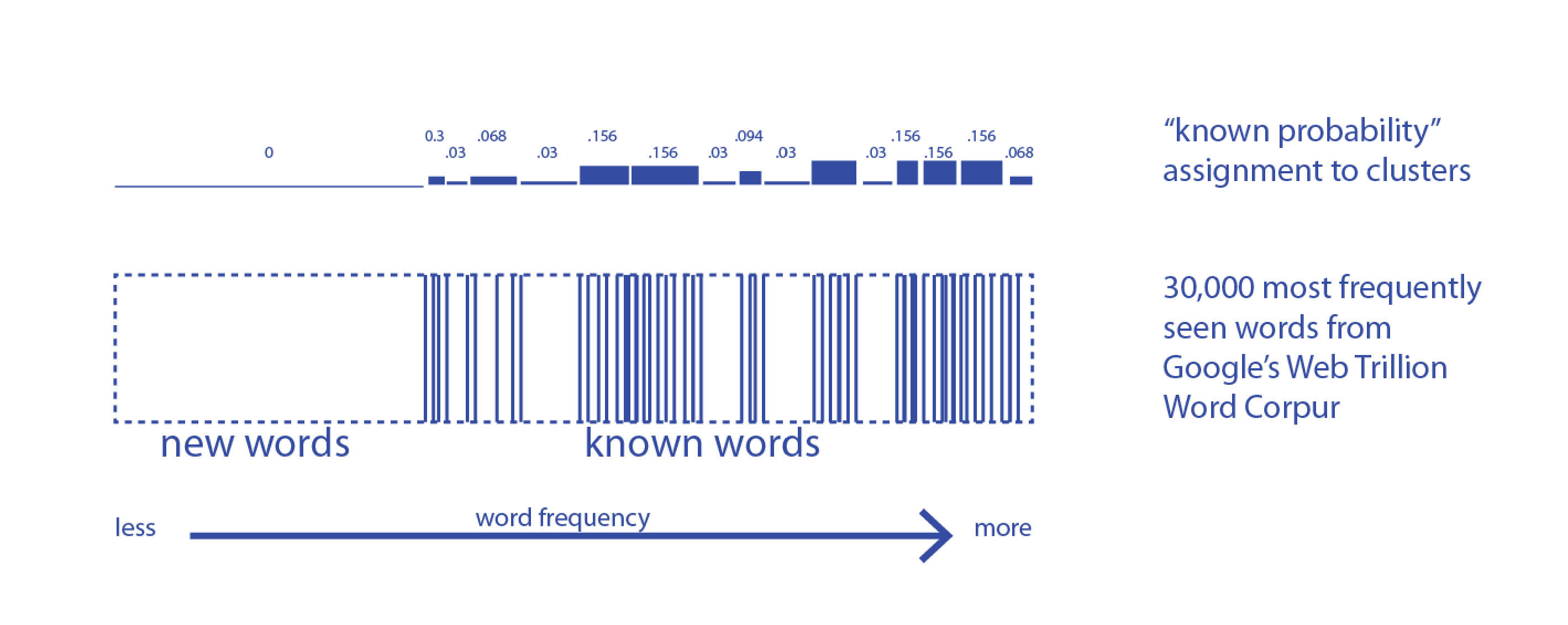
Backend Clustering Algorithm
The clustering algorithm in the backend predicts the probabilities of each synonym known to a user. The underlying assumption is that frequent words fall more on elementary reading levels while rare ones fall on more difficult levels. By proxy, the reading difficulty level of a word can be estimated using word frequencies. In this prototype, a sorted list of 30,000 words from Google's Web Trillion Word Corpus forms the vocabulary space. Based on real-time user interactions, the clustering algorithm partitions the vocabulary space and assigns a probability to each section according to the distribution densities of indicated known words. For instance, a region densely populated with known words has a higher known probability. In each subsequent search, synonyms with known probabilities above the mean are automatically highlighted.